[Before starting the MSc in Library Science at City University London, one of my jobs in the LIS sector was being a Trainee Cataloguer for a library supply company. This blog post is a modified version of the research notes I made whilst preparing for a presentation on classification that I gave during that time.]
What is classification?
Classification is the practice of giving a book, or other library item, an identifying number (or series of numbers and letters, depending on the classification scheme used) which is determined by its subject matter. The classification is used to create a call number which is attached to the item record in the library’s catalogue, and a shelfmark, which is displayed on the book itself. The classification also forms part of the item’s bibliographic record, and is present in one or more MARC fields.

Simplified MARC records including both Library of Congress Classification (050 field) and Dewey Decimal Classification (082) numbers (click to enlarge).
Why classify?
- Library management: classification by subject matter allows a library to manage its collection effectively, by keeping material on a certain subject together in one place. Before the invention of modern classification schemes in the mid-to-late nineteenth century, books were classified according to their location within the library, which led to a lack of consistency between libraries and the inconvenience of reclassifying material whenever sections of the collection were moved around.
- User access: the greater convenience of using such a classification system also extends into the library’s electronic catalogue: for instance, a user can quickly browse items covering a particular topic by searching for its classification number. As the classification is an abbreviated expression of the content of the book (and sometimes other bibliographic information such as the author or title), the use of such a scheme in conjunction with spine labels and other signage also allows for quicker and more effective browsing of the library shelves.
- Efficiency: as with cataloguing standards in general, the widespread use of international classification schemes such as Dewey Decimal Classification (DDC) and Library of Congress Classification (LCC) allows for greater efficiency, as libraries can share the workload of classifying the thousands upon thousands of new books that are published each year, and also updating those that are antiquated.
Dewey Decimal Classification
Dewey Decimal Classification (DDC) is hierarchical — consisting of the division of subjects from the most general to the most specific, expressed in a form of controlled vocabulary — and uses pure notation (only numbers). The numbers for more general subjects can be found in the schedules (the printed or online list of classifications and rules), and classifications for those that are more complex or detailed can be constructed using number building, using standard divisions enumerated in additional tables. To facilitate searching, there is also a relative index of terms used in the schedule, so called because it shows the relation of the term to all of the disciplines in which it is found. These features and principles are demonstrated in this example, featuring a real book!
(“Forest Phoenix: How a great forest recovers after wildfire / David Lindenmayer, David Blair, Lachlan McBurney and Sam Banks.” ISBN: 9780643100343)

When books classified according to the DDC are shelved, they look something like this:
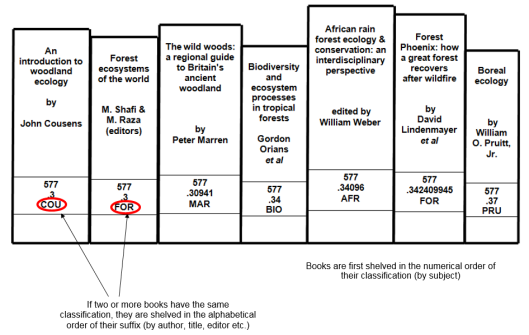
The DDC was invented by Melvil Dewey, who published the first version of the scheme in 1876. An LIS pioneer, Dewey founded the world’s first library school (attached to Columbia College) and co-founded the American Library Association, and was an advocate for causes such as the metric system and English spelling reform (his given name was originally “Melville”, for instance). He later described how he came up with the idea of using numbers to represent concepts, a simple yet revolutionary concept:
For months I dreamd night and day that there must be somewhere a satisfactory solution. After months of study, one Sunday during a long sermon by Pres. Stearns, while I lookt stedfastly at him without hearing a word, my mind absorbed in the vital problem, the solution flashed over me so that I jumpt in my seat and came very near shouting ‘Eureka’! It was to get absolute simplicity by using the simplest known symbols, the Arabic numerals as decimals, with the ordinary significance of nought, to number a classification of all human knowledge in print.
[Dewey, M. (1920) Decimal classification beginning, Library Journal, 45, no. 15, February 1920, 151-154.]
The core principles of Dewey have remained the same, with much of the updates reflecting detail changes in the assignment of numbers to new or growing fields of study, although the use of standard codes listed in supplementary tables to enable number building was an important development in response to the faceted (or analytico-synthetic) Colon Classification devised several decades later by S. R. Ranganathan. The DDC also forms the basis of the Universal Decimal System developed by Paul Otlet and Henri La Fontaine, which also includes greater scope for faceted classification and is suitable for extremely large collections.
Now in its 23rd edition, it is currently owned and maintained by the Online Computer Library Center (OCLC) Although the full details of the classification scheme must be purchased — either in three hefty print volumes or as a subscription to the online version, WebDewey — a simplified version is available in linked data format. Although it has faced criticism for a number of reasons, including its Anglo-American world-view bias, it is still the most popular classification scheme in the world: by the OCLC’s own estimates, it is used by over 200,000 libraries in over 135 countries, including over sixty national bibliographies.
Library of Congress Classification
Library of Congress Classification (LCC) is far more enumerative, in that it lists as many subjects in the schedules as possible (and thus is significantly more detailed than DDC) and uses alphanumeric notation (including Cutter Numbers, which follow a code to arrange text in alphabetic order using the fewest possible characters). There is some scope for number building, but less so than in DCC. Due to the greater size of the schedules, there is no overall index, but each general section has its own. These are not relative and therefore are more complicated to search. In general, the LCC system is less intuitive and more prescriptive than DDC due to its enumerative nature. Unlike DDC, the intention of LCC is that each item in a library (excluding duplicates) should have a unique shelfmark. Using the same book as before as an example, LCC produces a very different shelfmark to DDC:

Unlike with DDC, the author’s name/title is an intrinsic part of the classification itself.
Geographic Cutter numbers are derived from an international standard. Author/title Cutter numbers are constructed by the cataloguer using standard alpha-numeric tables (or created using an online tool), but may need to be adjusted based on the library’s existing collection to ensure that no two different items share the same shelfmark (for example, the title Cutter could be changed to F648 if F65 was already taken by a book on the same subject and with a similar title or a single/primary author named, e.g. Forrester).
When books classified according to the LCC are shelved, they look something like this:
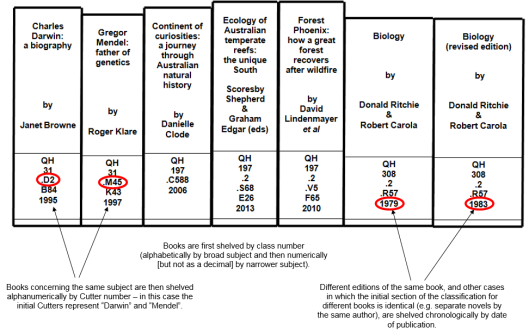
As the name suggests, the LCC was devised by Herbert Putnam (with assistance from Charles Ammi Cutter and his Expansive Classification scheme to organise the books and other materials in the United States legislature’s collection, and can thus also be criticised for much the same Anglo-American bias that exists in the DDC, in addition to the fact that, as a practical scheme initially intended for the demands of a particular library, it lacks an sound epistemological basis. Unlike the DDC, it has been updated irregularly by subject area, and its main schedules are also available online, as downloadable Word documents or as linked data. It is also supported as an information organisation tool by the Library of Congress Subject Headings.
A note on individual judgement
Most books are classified as they are published (known as Cataloguing-In-Publication) by recognised cataloguing authorities (e.g. Library of Congress, British Library) and their classifications can simply be reused. However, the classifier may be called upon to use his or her own judgement (memorably described by the leader of our recent cataloguing workshops, Deborah Lee as the “cherry on top” of the cake of guidance notes, policies and institutional preferences that can result in a deviation from “normal” procedure), in the case of:
- the existing record containing an error, typographical or otherwise;
- the existing record being outdated and using a classification that has since been relocated or discontinued;
- the newly-published item having yet to be catalogued or classified by an authority;
- the item only having a classification in one particular scheme whereas the library requires another;
- the item not having a record for miscellaneous reasons (extreme age, limited publication, published abroad, etc.)
In addition, although the schemes are extremely detailed and cover the entire breadth of human knowledge, classification can still be open to interpretation. For example, a work covering the women’s suffrage movement in Britain, but also women’s wider social role and experience at the time, could conceivably be classified under several different Dewey numbers, a selection of which follows:

The colour-coding demonstrates that the same subject matter can be incorporated in different orders to create various classifications. This feature of classification schemes is known as the Acknowledgment of Duplication.
Moreover, local library preferences may require amendments to the “pure” classifications, such as the truncation of long classifications, the avoidance of certain subdivisions, the relocation of classifications for certain topics, or even a mix of two different classification systems.
What is the future of classification?
The astute reader will doubtless have noted that much of what I have written need only be applied to library resources that exist in the form of physical entities. There is no intrinsic need to classify electronic or Internet-based resources using the existing methods, as the information contained within them is stored, and can be retrieved, in ways that transcend the traditional trappings of shelf-space and the physical library environment—although that hasn’t stopped some Internet classification projects from being carried out!
Nevertheless, it is fair to say that, so long as information exists, humanity will always need to organise it, and continually be developing tools to do so to best effect. It is equally fair to say that, although library collections are increasingly moving towards the digital, it is hard to envision the traditional media of books, journals and other print media, and their corresponding rows of shelving, being totally superseded any time soon.
[N.B. The featured image from this post is a public-domain photograph, taken by Carol M. Highsmith, of the main Reading Room at the Library of Congress. Source: Wikimedia Commons.]