Tags
Artists Books Online, authority control, BIBFRAME, Darcy DiNucci, DITA, Dublin Core Metadata Initiative, HTML, information architecture, information management, markup languages, metadata, Old Bailey Online, OWL, RDF, Semantic Web, Text Encoding Inititative, Tim Berners-Lee, W3C, Wikipedia, XML
The term “Web 2.0” was coined by Darcy DiNucci in 1999 and has gained credence during the 21st century. “Web 1.0” (which is of course a retronym as this term was not used at the time) pages were largely static, text-based and passively consumed by those who accessed them—with the notable exception of the hyperlink, they were essentially a continuation of a printed book, journal, newspaper article or a similar pre-Internet resources. In contrast, Web 2.0 was (and still is!) all about a dynamic, interactive user experience, involving multimedia messages, “mashups” of different website features using APIs, and user participation through social media, of which this blog is itself an example.
However, as interesting and meaningful as Web 2.0 may be to us, the human consumers, it is still flat and devoid of semantic information to our computers, the intermediaries. This is where the concept of the Semantic Web—also known as Web 3.0—comes in. It is a project spearheaded by the World Wide Web Consortium (W3C) and coined by Tim Berners-Lee, and aims to produce a Web of meaningful information (hence “semantic”) that can be understood—not just read—by machines. The technology that underlies this aim is the encoding of all text with metadata, using standard markup languages (such as XML) and controlled grammars and vocabularies (such as those provided by the Dublin Core Metadata Initiative). The meaningful metadata is added using linked data, which on the Internet is primarily achieved by using the standardised Resource Description Framework (RDF). RDF is used to describe entities using a tripartite Subject—Predicate—Object model. For example, Dominic Allington-Smith (subject) studies at (predicate) City University London (object). When properly marked-up, this enables a machine to understand the nature of the relationship between the three elements, whereas the Web 2.0 can only identify that a relationship exists without knowing its nature. Those of you who have read my previous post on library metadata standards in the Web 2.0 era may be interested to know that the emerging BIBFRAME bibliographic metadata standard is expressed in RDF.
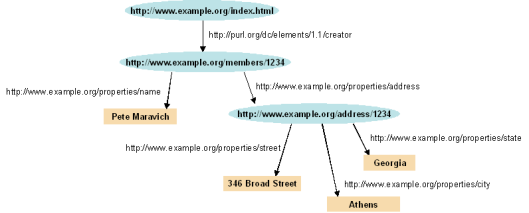
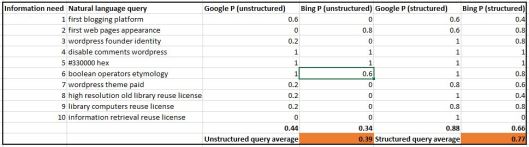
An example of a series of RDF relationships displayed in graph form. The blue ovals are subjects, the nodes predicates, and the beige rectangles are subjects (the lower two blue ovals are both objects and subjects). The Uniform Resource Identifiers (URIs) labelling the nodes link to standards which define the nature of the predicate. The hierarchy is controlled by the underlying Taxonomy and any limitations by the Ontology (see below).
Of course, markup languages have existed since the genesis of the Internet. One of the fundamental building blocks of the Web as we know it is the HyperText Markup Language (HTML), which is used to format webpages, but this is extremely limited as it does not distinguish the meaningful content of text, just how it should be presented. This can be demonstrated in the Google Chrome browser by pressing Ctrl+U when viewing this or any other page in this blog to view its source code—although the markup is extensive and pervasive, it only refers to how the page is displayed on the computer screen; not its semantic meaning. The concept of the Semantic Web is different, as all text is marked-up with meaningful metadata, forcing the machine reading it to make explicit interventions in order to interpret it, thus making it open to searching, analysis and to be placed into relationships with other texts in the corpus (I should point out that current search engines are inefficient by comparison, as they must make guesses—albeit increasingly well-educated ones—on the content of text that has not been marked-up based on context and collocation).
One way in which it may be useful to visualise the concept of the Semantic Web is by referring to the ill-fated Allwiki campaign, an argument during the early years of Wikipedia that every single word in an article should be linked to another Wikipedia article, or its definition on sister project Wiktionary, instead of the accepted current model. The Semantic Web, however, is different: whereas linking every single word in a Wikipedia article is immediately obvious to the human reader, the XML or similar markup language that can be used to encode the entire contents of a webpage is not visible in the human-readable interface, and is instead only intended for consumption by the machine that uses the information to display, search (and so forth) the page.
Although the vast majority of the content available through the Internet is currently not semantic, many research projects exist that have marked-up their entire corpora of source material, digitised or otherwise, with metadata, using the principles laid out by the Text Encoding Initiative. This gives us an idea of how Web 3.0 could look. Due to the customisations needed for supporting the Semantic Web when dealing with different disciplines, contexts and so forth, it is also necessary to create a Document Type Definition, a Taxonomy (a hierarchical organisation of concepts derived from the RDF metadata suitable for use with the hierarchical nature of XML), and an Ontology (a collection of logical rules and inferences that can be applied to the Taxonomy, for example X did not influence Y if X lived before Y) in the Web Ontology Language (OWL).
The first of these research projects is the Old Bailey Online archive (used last week!). Its corpus of court cases and supplementary material has been entirely marked-up—using both manual and computerised processes—in order so that it may be searched more effectively. For an example, let us refer to the trial of Thomas Smith for murder in 1760: the link shows the digitised natural language text (with links to scans of the original, handwritten records), and this one shows the same text with its structured, hierarchical metadata included in XML. The extensive use of hierarchical categories of information using a customised, controlled vocabulary, means that the site can use a complex, faceted search engine to make best research use of the entire corpus. As I demonstrated last week, this XML data can also be exported into Voyant Tools for further analysis.
The second such project is Artists’ Books Online, “an online repository of facsimiles, metadata, and criticism”. The “About the Project” page provides full and detailed information about the website’s DTD, metadata, taxonomy, markup scheme, and other technical information. It is unfortunately not possible to view each repository item’s metadata in the XML format, but a sample markup webpage allows us to compare a sample of the machine-readable semantic metadata in XML (and some presentation information in HTML):
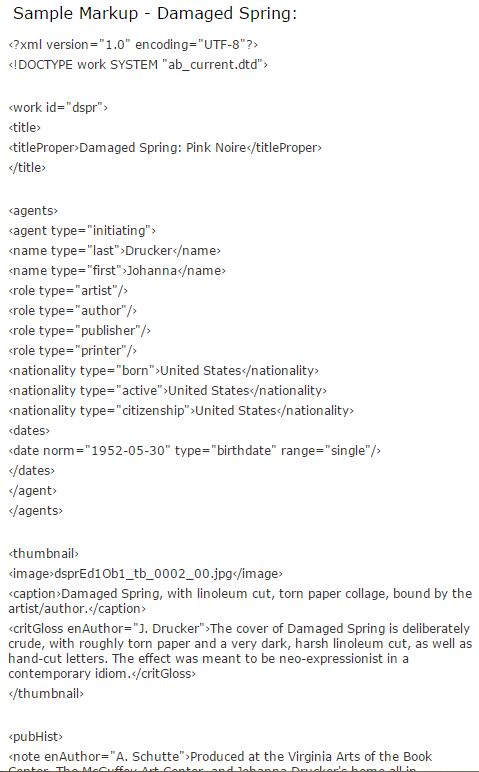
Compare with the beginning of the human-readable output on the same item’s normal webpage listing:

As with the Old Bailey Online project, the inclusion of meaningful metadata as an integral part of the webpage’s text allows for much greater efficiency in searching for, and comparing between, different sections of the total research corpus. Applying these principles to the entirety of the Internet may seem like a distant dream, but the rate of technological progress and innovation that resulted in Web 1.0 and 2.0 must surely make the realisation of Version 3.0 achievable.