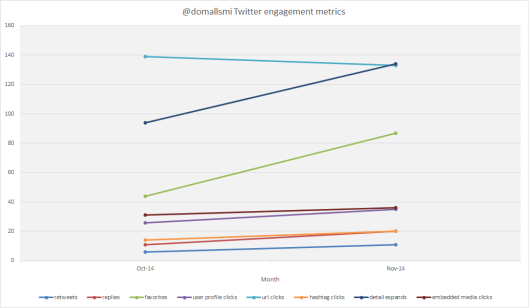
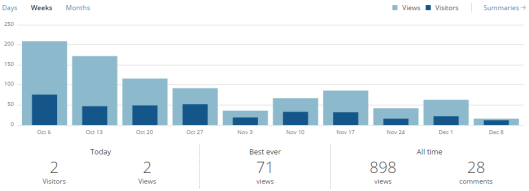
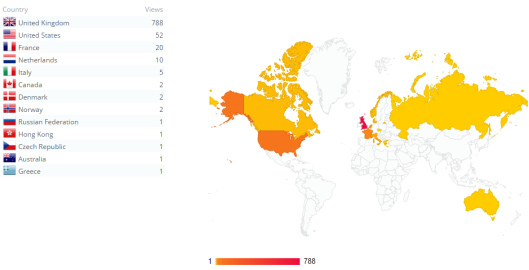
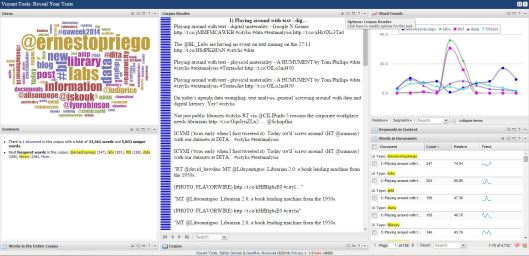
After last week’s experiments with word clouds and other forms of text analysis, our class took a step back yesterday to look at the wider implications of data mining (of which text analysis is a subset). These include questions of representation and of legality—for example, should data mining be exempt from copyright laws, allowing researchers to access full texts of copyrighted works in order to feed them through computer programmes and applications, with only the general conclusions being made available to the public instead of full individual texts?
Google Books’s ongoing digitisation project is a good example of the legal challenges involved; the associated website includes a brief (and self-justifying!) outline. It is worth bearing in mind that the aims of this particular project go beyond data mining, but one of the most visible outcomes is the creation of the Google Books Ngram Viewer, a tool which allows anyone to search the entire corpus of digitised material for certain words or phrases, in order to find out their levels of incidence (a technique given the name “n-gram”). The viewer covers the years 1800 to 2008 and incorporates corpora in various languages. The total number of books in the various corpora was 5.2&nsbp;million in 2012 and is growing rapidly; it still represents a small fraction of the total number of texts published or still available, but one that is becoming ever-increasingly representative of this total. Some institutions, such as the Royal Dutch Library (Koninklijke Bibliotheek) have also used the tool’s API to create their own “mashups”—in this case, a Dutch-language version of the tool with its own corpus.
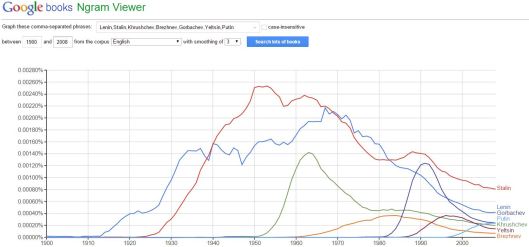
The Google Books Ngram Viewer can be used, in a manner similar to word clouds, to provide a quick and easy-to-understand overview of the criteria searched for. For example, this search of the most notable leaders of the Soviet Union/Russian Federation since the October Revolution in 1917 produces the following results from Google’s English corpus, showing rapid rises for each new leader as he assumed power, followed by either sustained or transient interest thereafter. One can easily imagine a humanities scholar using the tool as a starting-point for further research (perhaps using the further links to precise listings within Google Books that are conveniently placed underneath the generated graph!).
The tool can also be useful for LIS research: this graph shows the n-gram trends for several literacy concepts that we discussed in our Foundation module last week.
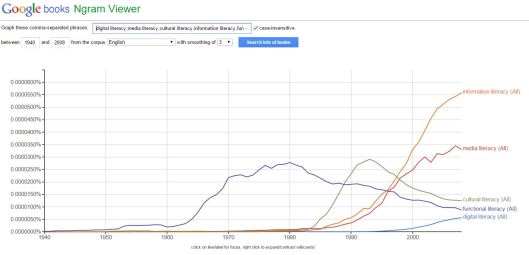
The graphs can also be embedded using an API, but not in WordPress.com thanks to its limited HTML functionality! (Please click to enlarge.)
Many of the institutions and publishers that do collaborate with Google perhaps do so reluctantly, unwilling to take on a corporate behemoth of such immense proportions. However, there are many examples of research projects in which the corpus, data mining and text analysis are carried out with much greater co-operation. One of these is Old Bailey Online, a project funded and otherwise supported by a variety of institutions and sources, which provides a digital archive of the court’s proceedings between 1674 and 1913. The website has a search engine, but also an API Demonstrator, which allows the results of interrogations of the database to be exported to the reference management system, Zotero, and the Voyant Tools suite of applications for data visualisation which I used last week.
It is therefore possible to carry out complex searches, analyse the results at a superficial level (yet one that can identify key research questions), before going through particularly interesting texts within the corpus in more detail. This is conventional “close reading”; the newer methods of data mining and text analysis have been referred to as “distant reading” by the digital humanities scholar, Franco Moretti.
One of the reasons for making the archive publicly available is so that those with an interest in genealogy can research their family history; sadly, my almost-unique surname restricts me from carrying out a search based on such principles without further research into my family history! Nevertheless, a search of the complete archive for cases in which someone was found guilty of “wounding”, but also found to be “insane”, produced a corpus which I was able to visualise using a number of methods: for example, in addition to the word clouds covered last week, I produced a graph showing the incidence of different weapons commonly used in the corpus of cases (which is listed in chronological order).
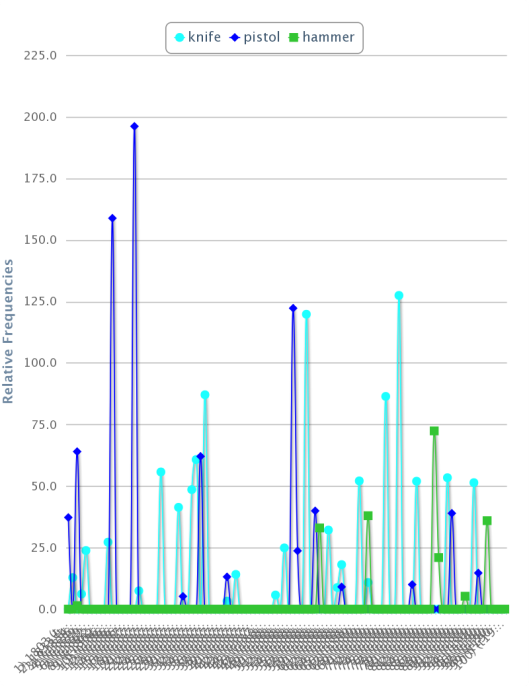
The keywords can then be further analysed with a collocation tool, and by close reading in the corpus reader.
During this process, I noticed that the integration between Old Bailey Online and Voyant Tools was particularly impressive: the export interface was extremely easy to use, and the common English stopwords list was applied automatically (which is not the case if the text is entered manually, as was the case last week).
Some research projects take this process a stage further, and create their own customised data mining and data visualisation tools to integrate all aspects of the project within the same digital framework. Although this takes a significant amount of work, it also produces potentially the most convenient and “future-proof” (in the sense that a project does not have to rely upon an external partner). The Dutch Utrect University currently has several text-mining research projects listed on its Digital Humanities website. Unfortunately, many of them are still in the early stages of development and do not provide access to the data being used, but a good example is the Circulation of Knowledge and Learned Practices in the 17th-century Dutch Republic (CKCC) project, whose corpus comprises 20,000 letters sent between seventeenth-century scholars (mostly) resident in the Dutch Republic.
The project, again funded by grants from an assortment of sponsors, is clear in its aims:
One of the main targets of this project is to create free, online access to historical sources, open to researchers from various disciplines all over the world. Unlike earlier printed editions of correspondences, this source is not static but of a highly dynamic nature, making it possible for the scholarly community to discuss problems, share information and add transcriptions or footnotes. One of the great advantages of this project is its ability to invoke new questions, new interpretations and new information, and to bring all this together on an expanding website.
To this end, the project’s website includes a Virtual Research Environment (VRE)—the ePistolarium—which allows anyone to search the corpus and produce visualisations from the data produced. The search engine offers a plethora of options: one can search by sender, recipient (or combine the two), people named in the letter, geographical location of sender or recipient, and date. There is also an algorithm that allows for a similarity search, whereby letters are ranked and retrieved based on similarities within the text.
A search for the complete correspondence available of Christiaan Huygens—one of the most prominent and well-represented individuals within the corpus—produces a list of results which can be ordered using six different criteria: date, sender, recipient, sender location, recipient location, and text search score (if performing a free text search in the body of the letters). The transcribed contents of each individual letter can also be read, along with its associated metadata, important keywords, and similar texts that are retrieved using the aforementioned similarity search tool. Each letter can also be sent to an e-mail address, or be shared on Facebook or Twitter, but unfortunately there are no permalinks as yet. The search results as a whole can also be exported as a CSV (Comma Separated Values) file, for those who may wish to perform their own further analysis.
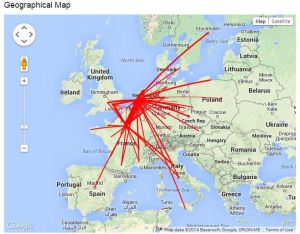
This would appear to be unnecessary, however, as the project has several different data visualisation tools that are fully integrated with the VRE. (The output for each visualisation is also available to download in JSON format, although it is not yet possible to embed any of them using an API.) The first of these is a map, in which the geographic location metadata associated with each letter is used to plot lines between senders and recipients on a map, in this case the correspondence of Huygens:
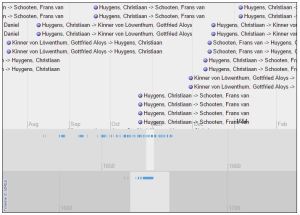
A movable timeline, in three different scales, allows the user to view patterns of Huygens’s correspondence in chronological order:
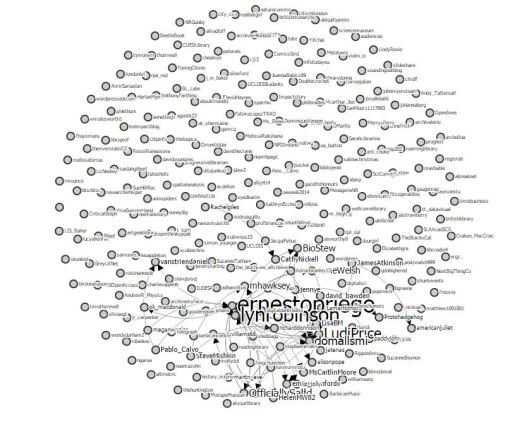
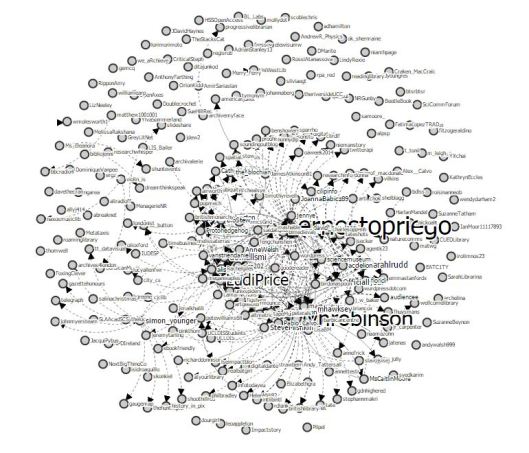
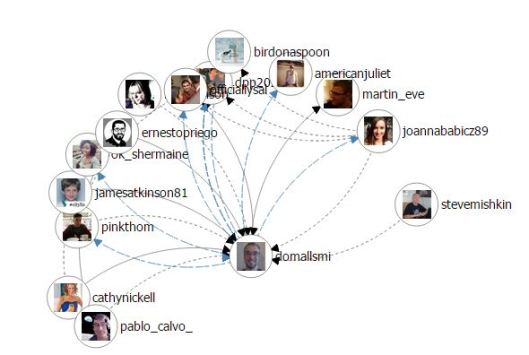
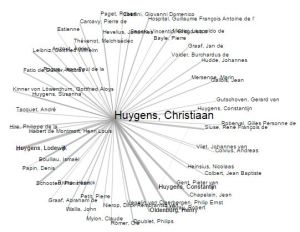
A network visualisation shows all the individuals to whom Huygens sent letters, and from whom he received them.
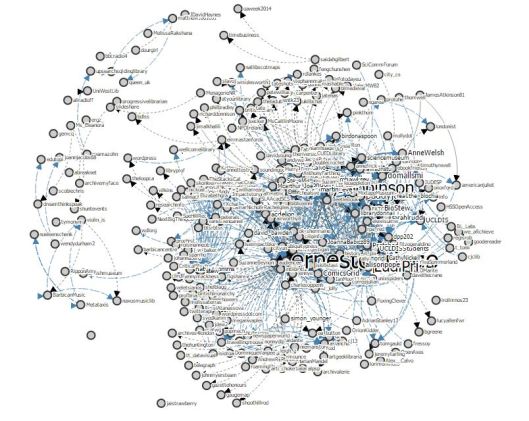
Finally, a “cocitation graph” shows the names of individuals, contemporary or otherwise, who feature in the correspondence. I believe that this visualisation is of the greatest value, as it allows us to view those who could be described as the intellectual influencers of Huygens and his peers, and acts as a useful starting-point for further research on this topic, which would involve close reading of the letters themselves. The project’s website includes a page of initial research experiments conducted with the tool.
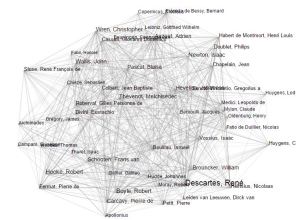
(Committed readers of this blog may notice a certain similarity between these latter two visualisations and those produced by the TAGS Explorer tool that I wrote about some weeks ago.)
It is clear from my own experience with these projects, and the topics that I have covered in previous blog posts, that the “distant reading” of large-scale datasets through various forms of data mining is a crucial part of contemporary humanities research. Our role as information professionals must therefore be to fully understand these tools and technologies in order to further advance the knowledge that can be produced, or at least assisted in producing, by them throughout academia and the wider world. It is worth noting once more, however, that these techniques should be used to supplement traditional research, so we must also endeavour to keep our feet on the ground whilst doing so.