
Tags
Andrei Broder, Bing, Boolean operators, databases, DITA, Google, information architecture, information management, information needs, information retrieval, natural language, search engines, structured queries, unstructured queries
For the information professional, there are two main ways of curating (for want of a better term) data. The first is by using a relational database—an extremely efficient way of organising information within an organisation—but this is not suitable for large quantities of heterogenous data that are owned by many different identities. For such datasets (this post will focus on the most obvious example, the contents of the World Wide Web), the alternative system of Information Retrieval (IR) comes into play.
An IR system consists of input (the content to be searched), indexing, search, and interface (how the user inputs their query into the system). Indexing requires the contents of the input (and possibly any accompanying metadata) to be identified, filtered, listed and stored. The storage medium can vary from the endpages of a book (in a traditional sense of the index function) to the vast array of servers used by a Web search engine.
The most important part of the IR system is the search component, which retrieves the information required by the user. A major advantage of modern IR systems over relational databases is that users can submit unstructured queries: instead of using set command lines, Boolean operators or similar standardised codes and expressions, the user can instead input unstructured queries in the form of natural language, or indeed in full questions.
Nevertheless, despite the constant advances in search algorithms used by search engines, promising greater and greater accuracy in using “best-match” search models to improve the quality of IR for unstructured queries, it should still be possible to achieve a greater degree of precision when inputting structured search terms into the same search engines. In the DITA module’s lab session yesterday, I tested this hypothesis by attempting to answer ten questions using first unstructured and then structured queries. To introduce a degree of competition, I used both Google and Bing—the former with the majority of the British search engine market, and the latter its fastest-growing competitor—truly two titans of the Internet Age!
The ten information needs were as follows:
- What was the first blogging platform?
- What did the first web pages look like?
- Who developed WordPress and when?
- How do you disable comments on WordPress.com blogs?
- What colour is produced with the #330000 HEX value?
- Why are they called “Boolean operators”?
- Find a WordPress theme for sale that you like or would consider paying for.
- Find a high-resolution photograph of an old library which is licensed for reuse.
- Find an image of computers in a library, licensed for reuse.
- Find an image to illustrate the concept of information retrieval, licensed for reuse.
Note that this includes a range of information needs, as defined by Andrei Broder’s taxonomy (2002), different media types, and a distinction between specific, well-defined queries, and more general ones which require a degree of browsing.
To generate my results, I used the same natural language search terms for both Google and Bing, before using a range of structured search techniques (mentioned above) and the search engines’ own “advanced search” tools in an attempt to refine the information retrieved. I measured the precision of the searches by taking the top five results (excluding adverts and sponsored results) and using the standard formula:
Precision (P) = Relevant results (Nr) / Total results (N) (i.e. 5)
This produced the following results (I have not included the structured queries in the table due to space limitations, as they were not the same for both search engines):
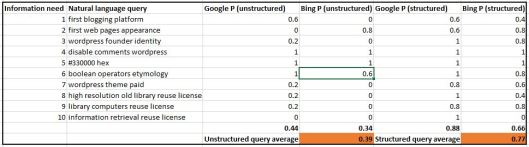
Click to enlarge
It is clear to see that the structured queries were almost twice as effective as those using natural language only. This was particularly true of the final three queries: these used the image search facility, which is far more reliant on the advanced settings tools to return relevant results. It is also clear that Google has a slight edge over Bing in both unstructured and structured queries (although this may have been skewed by the fact that I habitually use Google and am therefore more accustomed to searching with it). I was surprised by some of the inconsistencies between the two search engines, particularly in regard to the unstructured queries: for example, entering “first blogging platform” into Google in order to establish the identity of the first blogging platform in history produced a reasonable level of precision, whereas Bing returned a series of guides on how to blog for the first time—a situation which was reversed for the second information need concerning the appearance of early web pages. In general, it is also apparent that unstructured queries were most effective when searching for precise information (e.g. the colour produced by the #330000 HEX value), whereas structured queries were far superior for browsing (e.g. a suitable WordPress theme, or freely-licensed images to illustrate a particular point).
Finally, to demonstrate the value of this experiment, I conclude this post with a high-resolution, public-domain photograph of a beautiful old library.

Public domain, taken by Emgonzalez and uploaded to Wikimedia Commons.

This is a well-explained article and you are so professional when analysising statistics from your research. I would be interested to read your further posts !
LikeLike
Thank you. 🙂
LikeLike
This is a well-explained article. You are so professional when analysising statistics for your research. I would be interested to read your further posts!
LikeLike
Pingback: Information Retrieval and Relational Databases (in the library) | David Phillips on DITA
Pingback: Walking in a multimedia wonderland | Digital Information Technologies & Architectures
Pingback: Self-reflection through DITA data analysis | Digital Information Technologies & Architectures
Pingback: Learning about LIS at City University London part II: two terms of blogging in review | The Library of Tomorrow